本文最后更新于 2026年3月29日 晚上
前言 你是郑大的一名25级大一新生。2026年2月10日上午8点50分,漫不经心浏览着选课预览界面的你,脑中仍未形成清晰的选课目标。
“这个微生物与人类健康看上去挺不错的”
“材料·人·环境也行吧?”
“哎这睡眠革命感觉更有意思”
诸如此类的思绪不断自你的大脑产生。“学校怎么就让选两个啊,要是多给几个我肯定都选满。”不时也会有这样的想法飘过。
时间在这种心绪的影响下流逝地格外快。等终于选定目标,回过神来,已经不到一分钟了。你略微打起精神,准备在时间跳到9:00的那一瞬间刷新界面,飞快地点上两节课,然后美美回被窝打游戏,继续享受美好的假期时光。
是时候了————
你点击刷新,却发现页面一片空白。一阵不好的预感涌上心头,你有些慌乱,但还是佯装镇定,关闭浏览器界面重新尝试进入网页。
还是一片白。
此时的你终于意识到问题的严重性,迅速检查网络连接后,你第三次尝试登入选课界面。
一行大大的“504 Gateway Time-out”出现在页面上方。
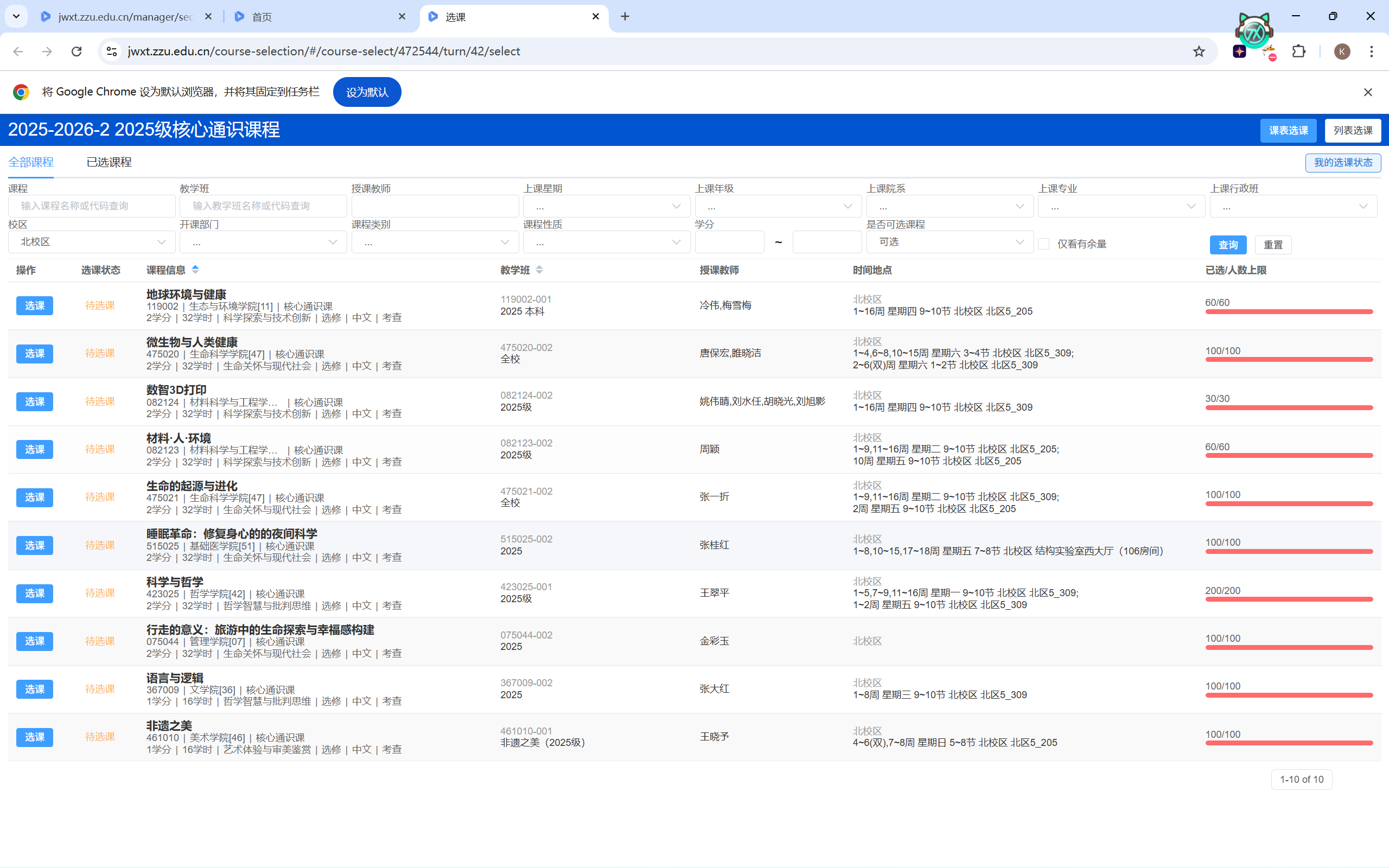
等你真正看到选课界面已经是十分钟后。映入眼帘的是这样一幅画面:
噔-噔-咚!
**(一阵尖锐的爆鸣声)**
虽然首战输的一塌糊涂,但作为一名血气方刚的大一新生,尤其是一名学计算机的大一新生,岂能忍受此等大辱。
于是你开始上网搜索“自动化抢课”关键词,并开始着手打造你的第一个抢课脚本。
(虽然因为python基础过于薄弱,一直拖到系统第二次开放才正式开始编写)
以上由本人真实经历改编。
大学抢选修课向来不是一件易事。正因如此,才会有人寻求更简洁、更高效的方式。本篇将分享我完成抢课脚本的经历,希望能够给你一点帮助。
思考:脚本的目的是? 发现课程全满之后我就释然了,可以静下心来思考这个问题:如果真的有这样一个脚本,我希望它能实现什么功能?仅仅是“抢课”这一模糊的说法吗?
就当时的处境而言,理所应当地,我希望有一个自动化工具能实时监测课程余量,并在空出位置后立即发送选课请求来达到“抢”的效果。
刷新也是很重要的一部分。众所周知这种校园网站的登录很容易就会过期,一旦过期就需要刷新界面重新登录。就是登录保持住了,定时刷新也能第一时间获取最新信息。
那既然都谈到登录了,何不把登录部分也一并自动化呢?到时候直接一键启动,连学号密码都不用我亲自输入了。
这样脚本就能大致分为两部分:登录和选课。
我的思路就是分别构建这两部分代码,再最终整合到一起。
登录部分 要让代码模拟人类的操作,那就得先看看我们自己是如何操作的。于我而言是这几步:
1.打开一个浏览器
2.点击预先收藏的教学服务平台快捷方式
3.点击学生端进入登录界面
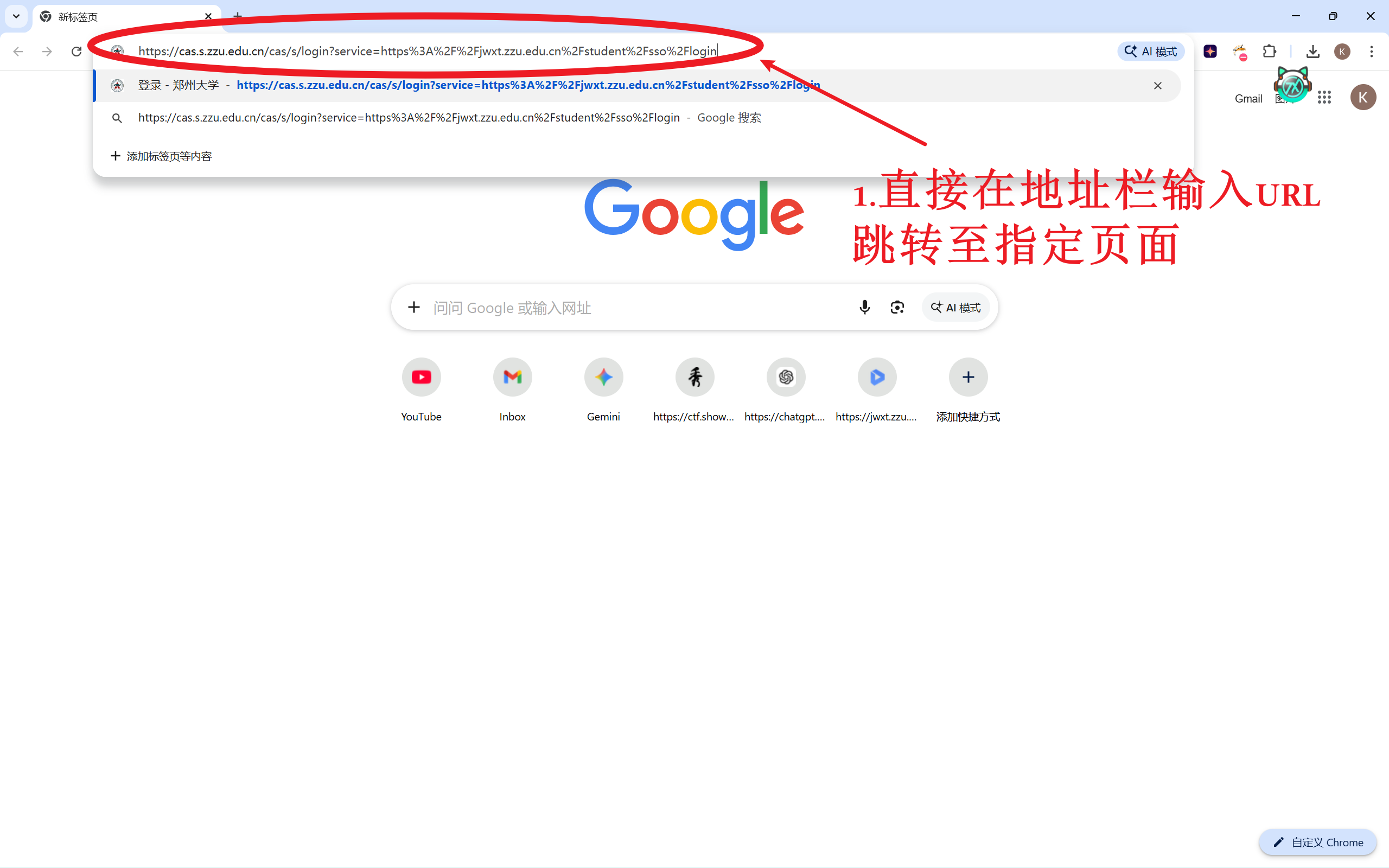
到这一步我就想到,既然到登录界面为止都可以直接在地址栏输入URL跳转,那这几步完全可以浓缩成一步。
重新思考流程:
浏览器网页+自动化+登录,去网上搜索或者问AI,大概率会告诉你这是playwright或者selenium库的舒适区。虽然playwright更加现代好用,不过博主学习的前辈们使用的都是selenium,这里就用传统方法啦~
这里通过Selenium库调用WebDriver API来控制浏览器,而webdriver需要搭配浏览器驱动食用。
博主使用Chrome浏览器,所以搞了一个Chromedriver。下载地址贴在下面了
Chrome:https://googlechromelabs.github.io/chrome-for-testing/#stable
Edge: https://developer.microsoft.com/zh-cn/microsoft-edge/tools/webdriver/?cs=3457492030&form=MA13LH
下载好浏览器驱动后一般要放在系统PATH目录,当然如果图省事,也可以像我一样扔进脚本同目录。
导入模块直接安排上全明星
1 2 3 4 5 6 from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.common.keys import Keys from selenium.webdriver.common.action_chains import ActionChains
接下来开始构建用于登录的函数。首先由于实际操作中网页可能会因各种不可抗力导致加载晚于预定时间,所以引入显式等待,它能有效解决由于网络延迟或异步加载导致的‘元素尚未渲染’问题,避免脚本因找不到元素而频繁闪退。
与普通的time.sleep相比,WebDriverWait的优点是不用等满时间,只要等到特定元素出现就能进行下一步。
1 wait = WebDriverWait(driver, 15 )
登录主体部分采用try-except结构,建立容错机制。
开始一步步实现逻辑:
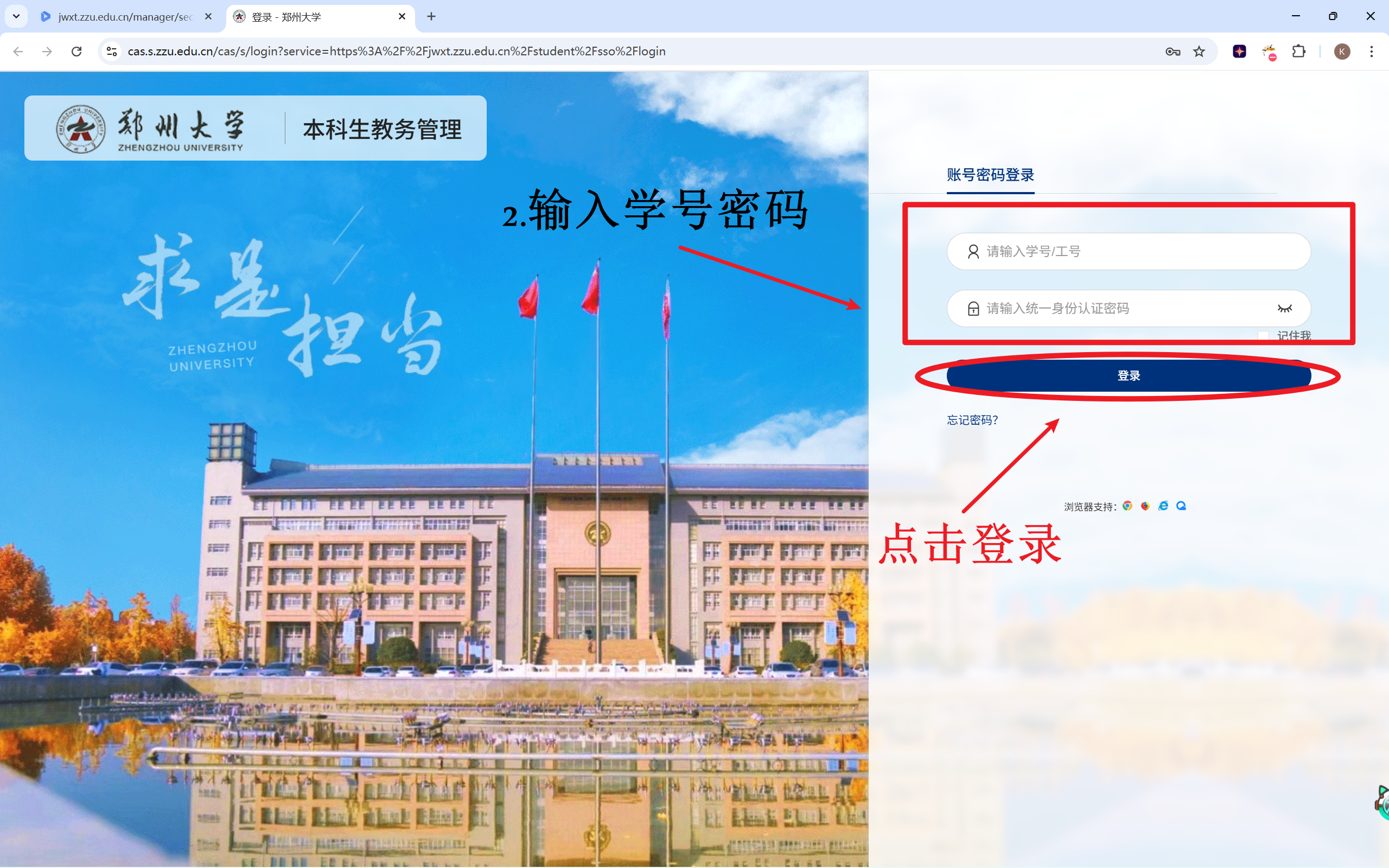
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 "input[placeholder='请输入学号/工号']" )"input[placeholder='请输入统一身份认证密码']" "login-btn" ).click()
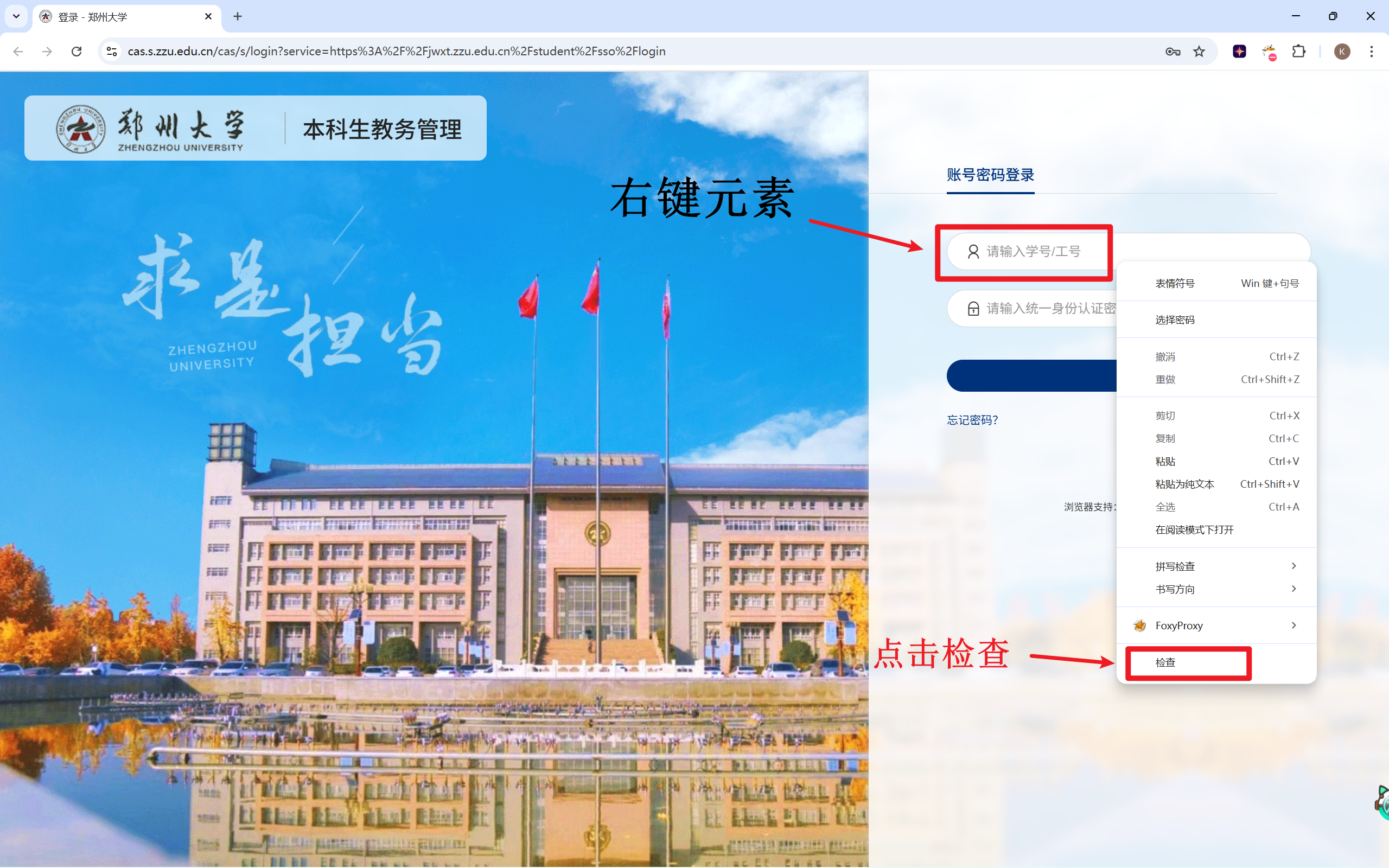
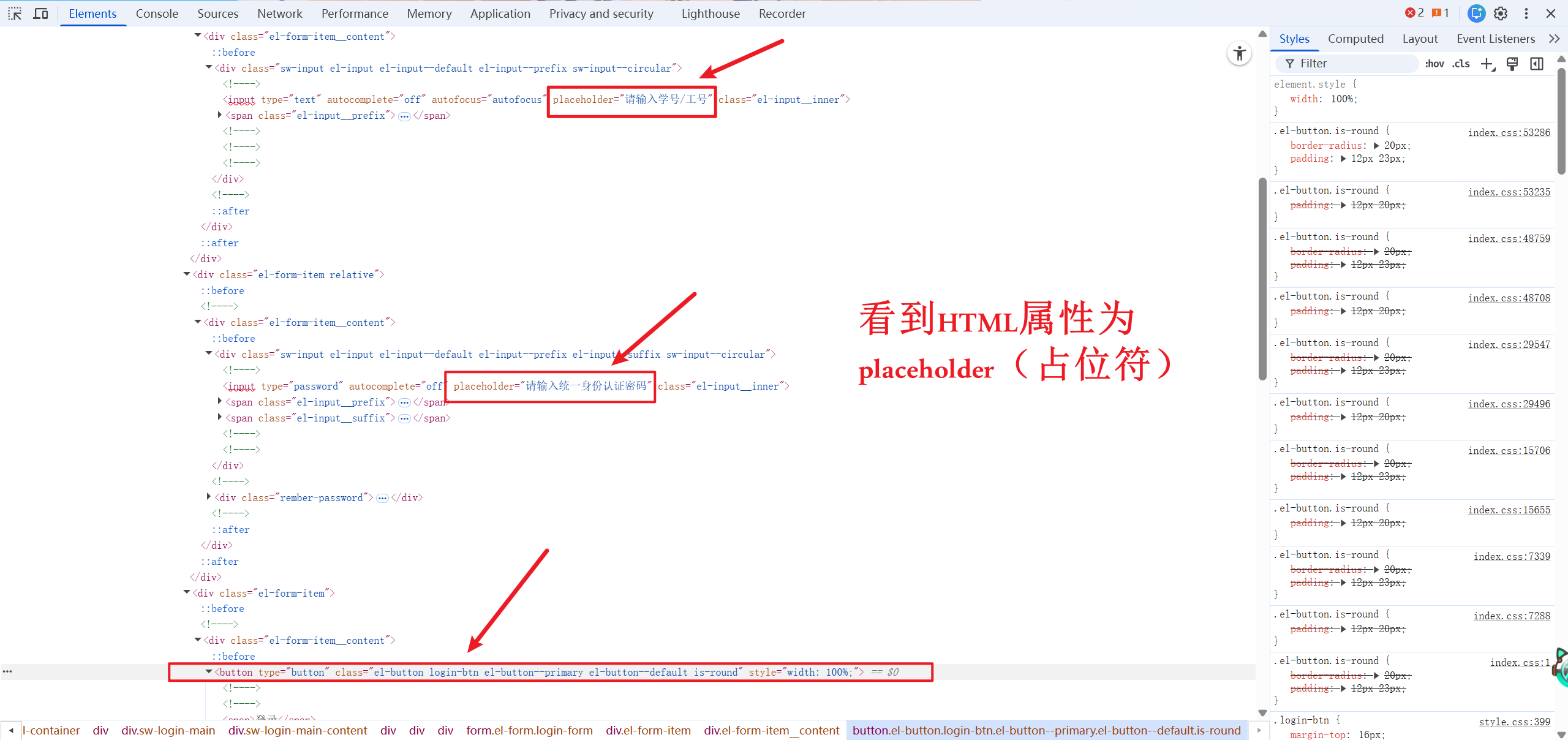
在输入学号和密码的位置,观察到标志文字,所以设定为发送数据的条件。
至于参数具体怎么写,还得用到网页的检查功能。
可以看到标志文字都是placeholder。而登录按钮虽然足足有5个class(el-button,login-btn,el-button--primary,el-button--default和is-round),但其中只有login-btn最唯一稳定,所以用这个属性来指代它。
点击登录后是页面第一次跳转,涉及到URL的改变,调用显示等待确保“选课”键出现并且可点击再进行下一步操作。
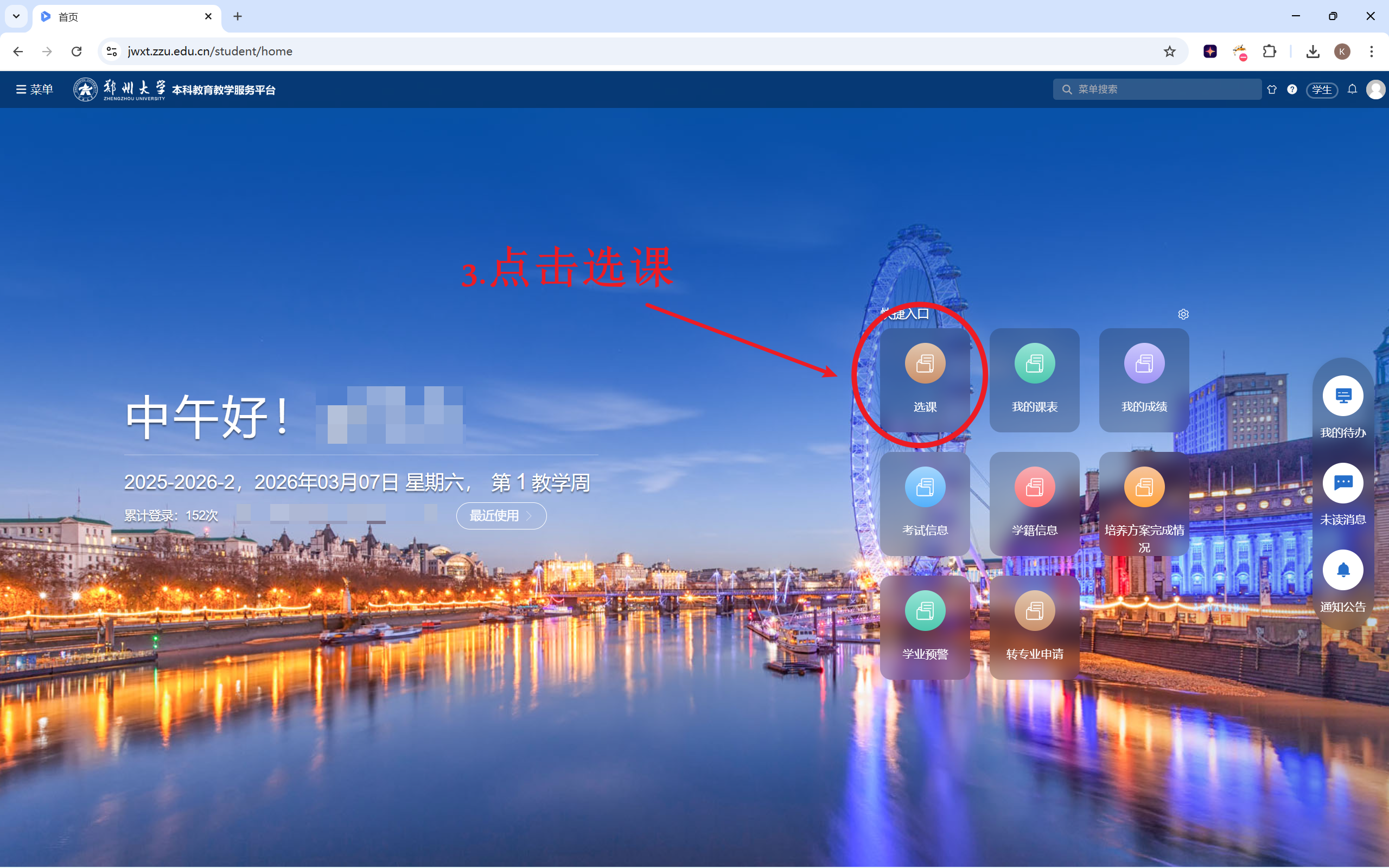
先检查一下选课元素的位置
结构相当于
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 <div class ="shortcut-panel" > <div class ="shortcut-item" > <div class ="shortcut-item__icon" > <svg class ="icon" > <use href ="#icon-system-wenjianguanli" > </use > </svg > </div > <div class ="shortcut-item__title" > </div > </div > </div >
“选课”两个字出现在shortcut-item__title这个div中,被shortcut-item对应的外层div包含。
构建XPATH定位选课图标
1 //div[contains(@class , 'shortcut-item' ) and .//div[contains(text(), '选课' )]]
翻译过来就是
找一个class里包含shortcut-item的div并且保证它的子元素里还有一个div,文字是’选课’。
激活这个相对路径
1 2 3 course_icon = wait.until(EC.element_to_be_clickable("//div[contains(@class, 'shortcut-item') and .//div[contains(text(), '选课')]]" )
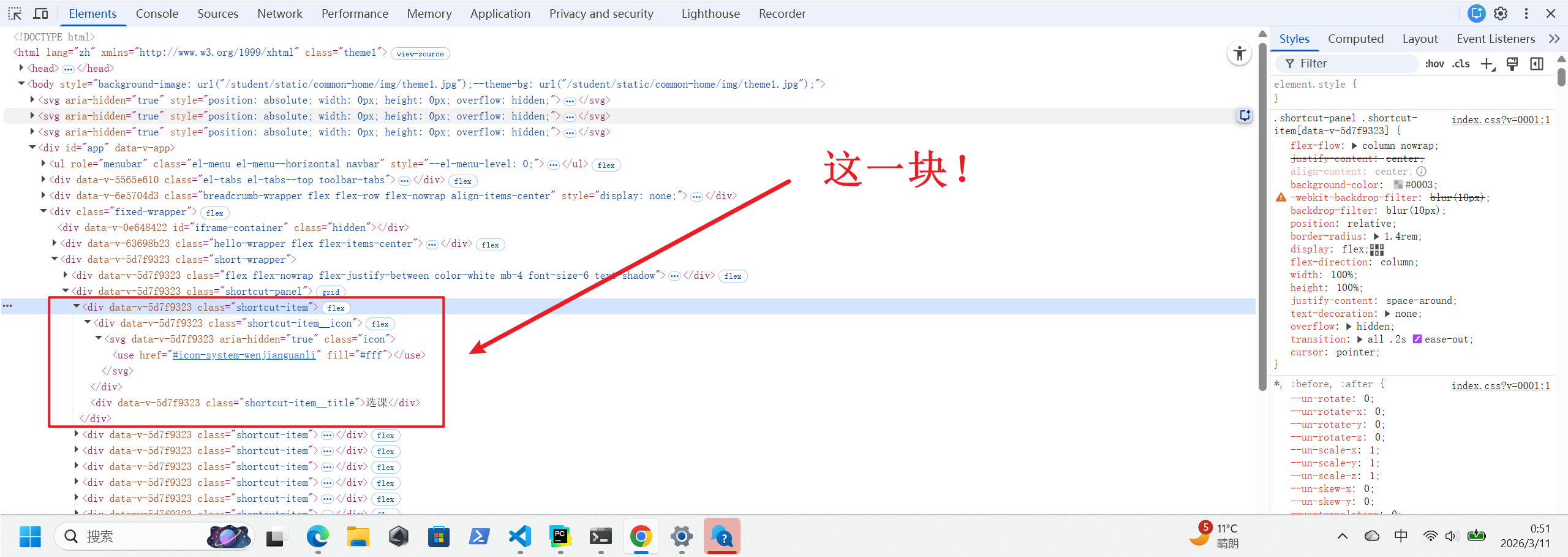
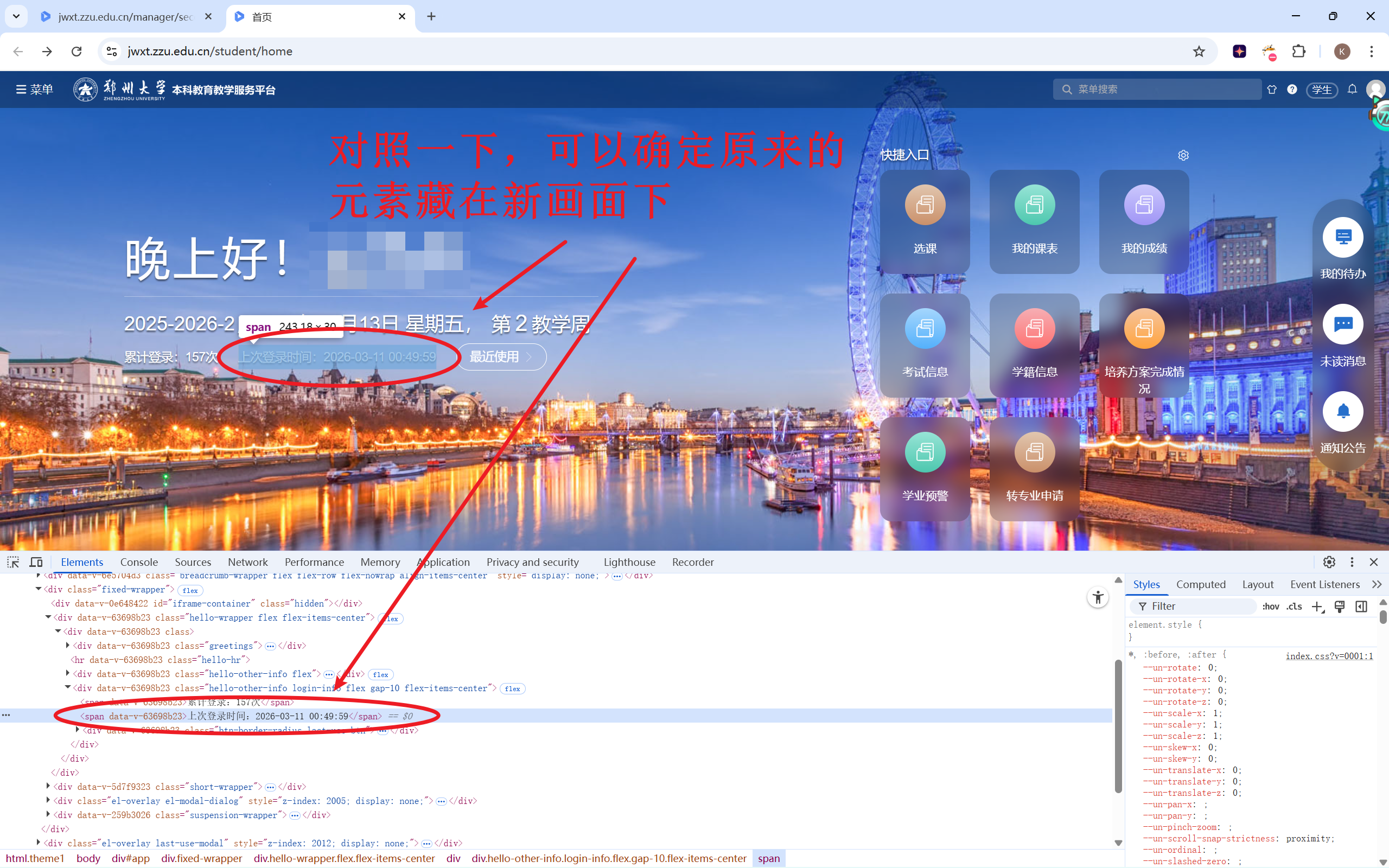
本来这里加上course_icon.click()点击一下就大功告成了,但看我前面放的流程图,点击“选课”后进入的步骤四对应页面的URL还是https://jwxt.zzu.edu.cn/student/home。这说明浏览器并不是打开了一个新的界面,而是在原有界面的基础上直接把新画面覆盖在上面。
用专业点的语言描述就是
“系统使用前端单页应用(SPA)架构:页面并不会重新加载,而是在当前页面内部动态渲染新的界面,把“选课系统”的内容覆盖显示出来,看起来像是进入了一个新的页面。”
用控制台来验证
这会导致一个问题,因为这种“重叠“的现象存在,导致脚本可能点不到我们想要的图层。
对于选课按钮,可以改用JS强制点击防止遮罩层干扰
1 driver.execute_script("arguments[0].click();" , course_icon)
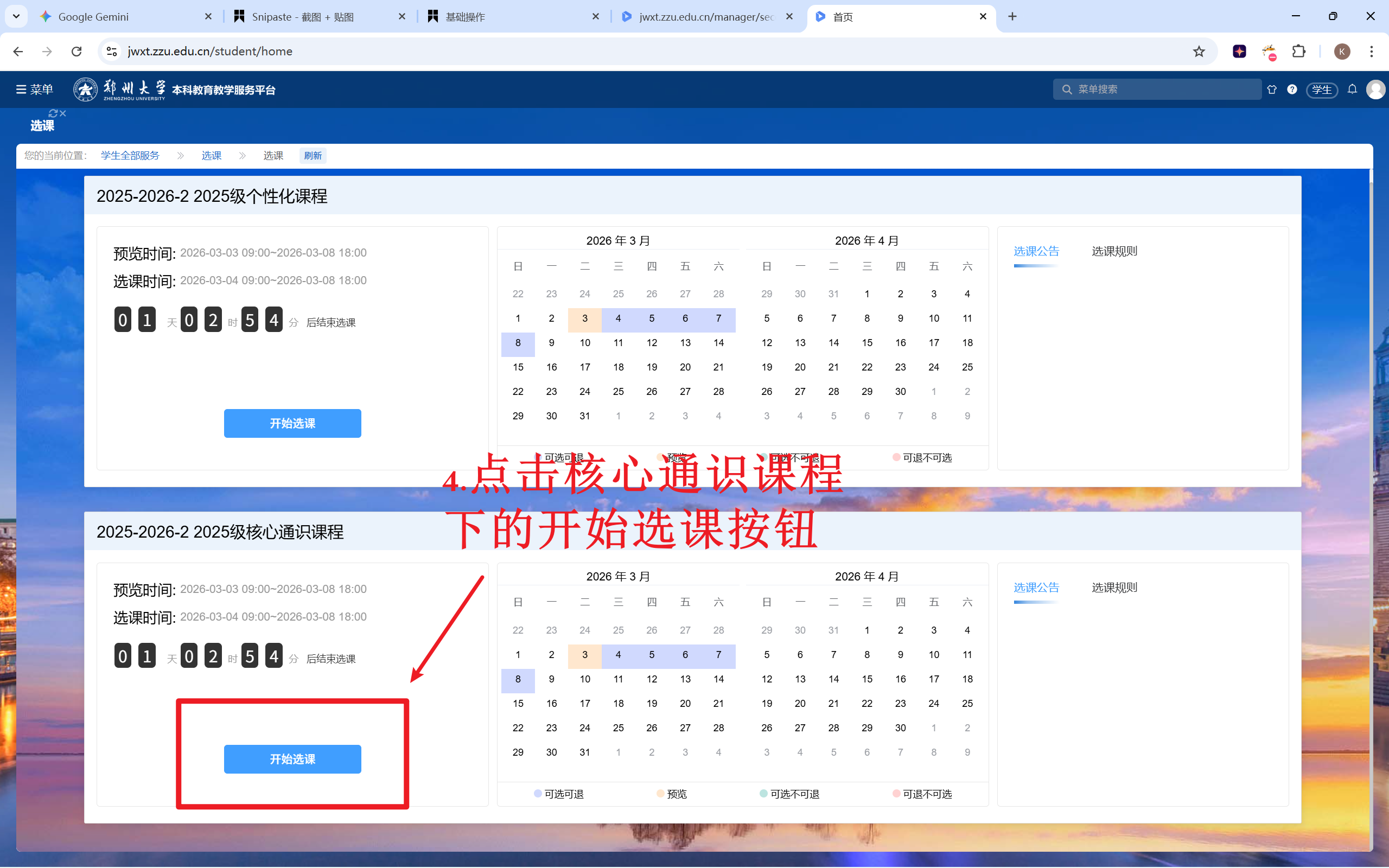
而对于第四步,要点击第二个蓝色的“开始选课”,这就很不友好。又是遮罩层又是相似元素,我尝试了好多次通过定位元素点击的方法都失败了。脚本似乎根本点不到遮罩层上,全都作用在了底层。
既然如此,那就换个思路。
我把目光转向了键盘控制。经过实验我发现,先点击一下页面(得在“您的当前位置”所在行以下),然后按三次Tab键,就能精准定位到第二个蓝色的“开始选课”按钮,再按一下enter便大功告成了。麻烦点就麻烦点吧,这是我能想到唯一可行的办法了。
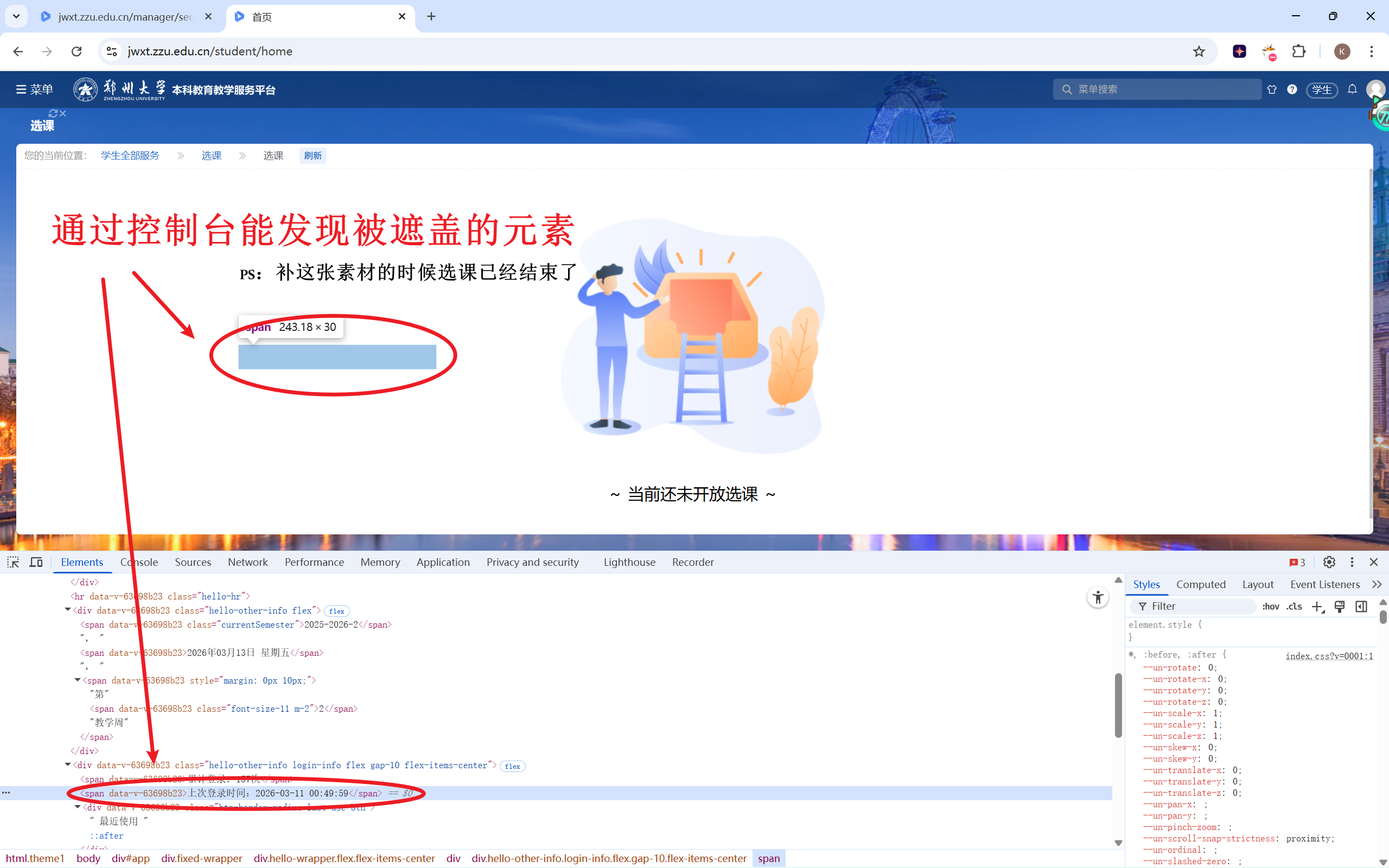
键盘控制交给Keys和ActionChains。对于一开始点击的那一下,反过来利用脚本只锁定底层元素的这一点,我随便找了个底层元素,就是刚才引用的图中的“上次登录时间”来让脚本点击对应位置。
实现如下
1 2 3 4 5 6 7 anchor = wait.until(EC.presence_of_element_located((By.XPATH, "//span[contains(text(), '上次登录时间')]" )))for _ in range (3 ):
wait+EC等待元素出现,ActionChains把鼠标移动到这个元素并点击,Keys执行三次Tab和一次Enter。这等价于我们点击了“开始选课”。
当然了,为了测试这个逻辑到底能不能通,最好还是加个验证环节。什么情况下算成功了?
“开始选课”被正确点击,页面跳转至最终选课界面,URL为https://jwxt.zzu.edu.cn/course-selection/#/course-select/student-id/turn/选课轮次/select时。
(ps:博主当时的选课轮次是42,以下不作重复说明)
就取这个URL当验证标准
1 2 3 4 5 6 7 for _ in range (10 ): for handle in driver.window_handles: if TARGET_URL_KEY in driver.current_url: print (f"[{time.strftime('%H:%M:%S' )} ] 成功跳转至指定页面,URL为 {driver.current_url} " )return True return False
补全try-except逻辑
1 2 3 except Exception as e:print (f"流程遇到错误: {e} " )return False
最终包装为run_login_flow(driver, student_id)。
剩下就是成功登录后的恢复+保活机制。这个就因平台而异了,一般每十分钟检查一次登录,三分钟刷新一次就行。至于怎么检查登录状态…还是等最后再解决吧。
选课部分 重头戏来了。所谓选课脚本,一定要能选课。对于这一核心功能,当然也可以直接让脚本模拟人的操作来点击按钮,但这样效率太低。你点击一次要花上一秒,可能还得刷新页面等加载,而别人发送一次网络请求只要100毫秒,差距一目了然。
为什么?绕过现象看本质,在线选课其实就是个浏览器帮你发HTTP请求的过程,但在我们能看到的部分,还有浏览器的渲染之类的“加工”,这就是耗时间的部分。采用发网络请求的方式可以绕过浏览器直接实现底层逻辑上的交互,体验飞一般的感觉。
打个比方吧,假如你要点外卖,一般人的做法是先打开APP,然后挑选->进店->备注->付款,中间得点击不同的按钮,赶上网络不好还得卡一会。而你不一样,你认识那家店老板,直接电话打过去点餐,然后一个微信转账,之后等着就可以了。
主播主播,道理我懂了,具体怎么操作呢?
代入我当时的视角,咱们一步一步来。
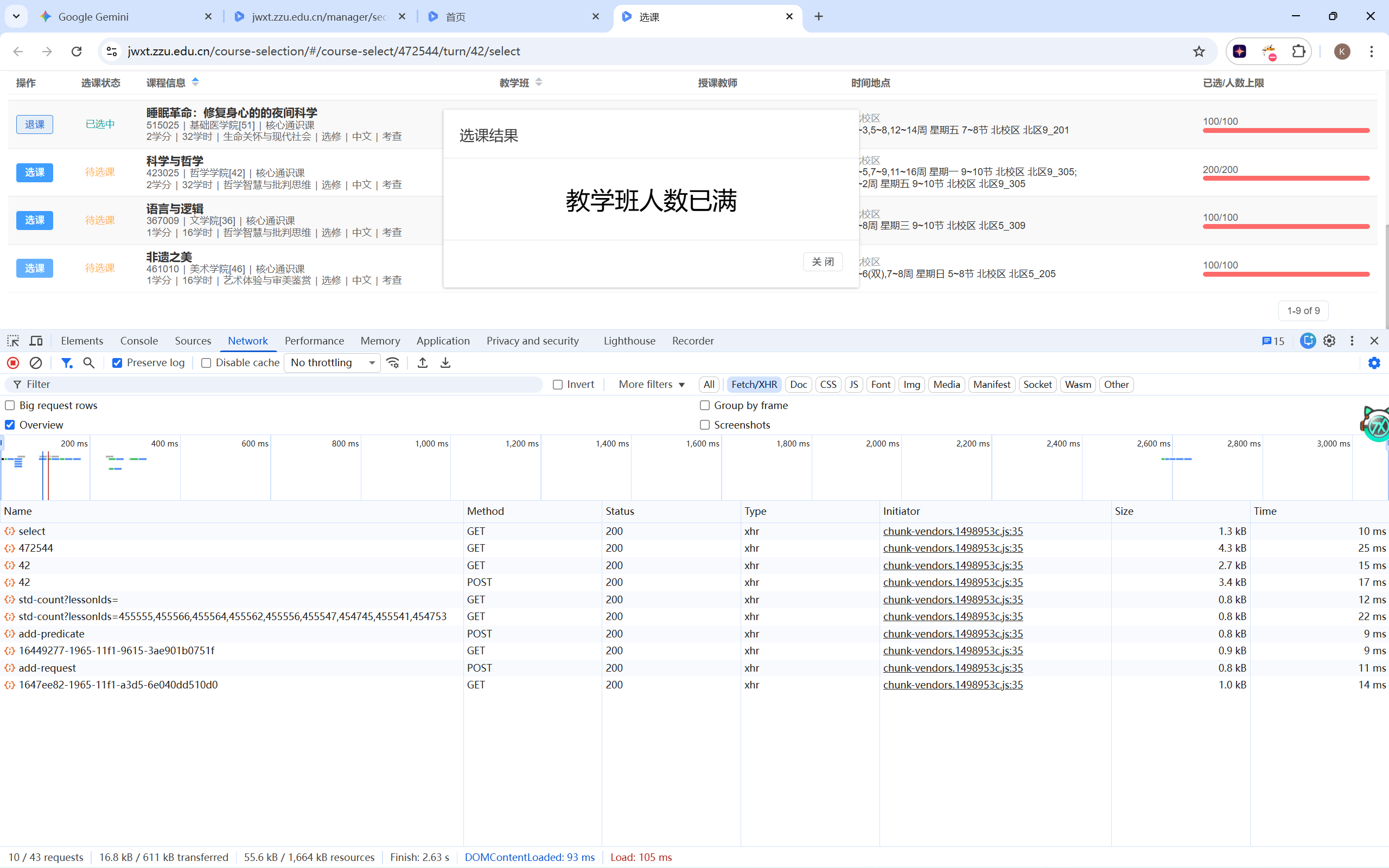
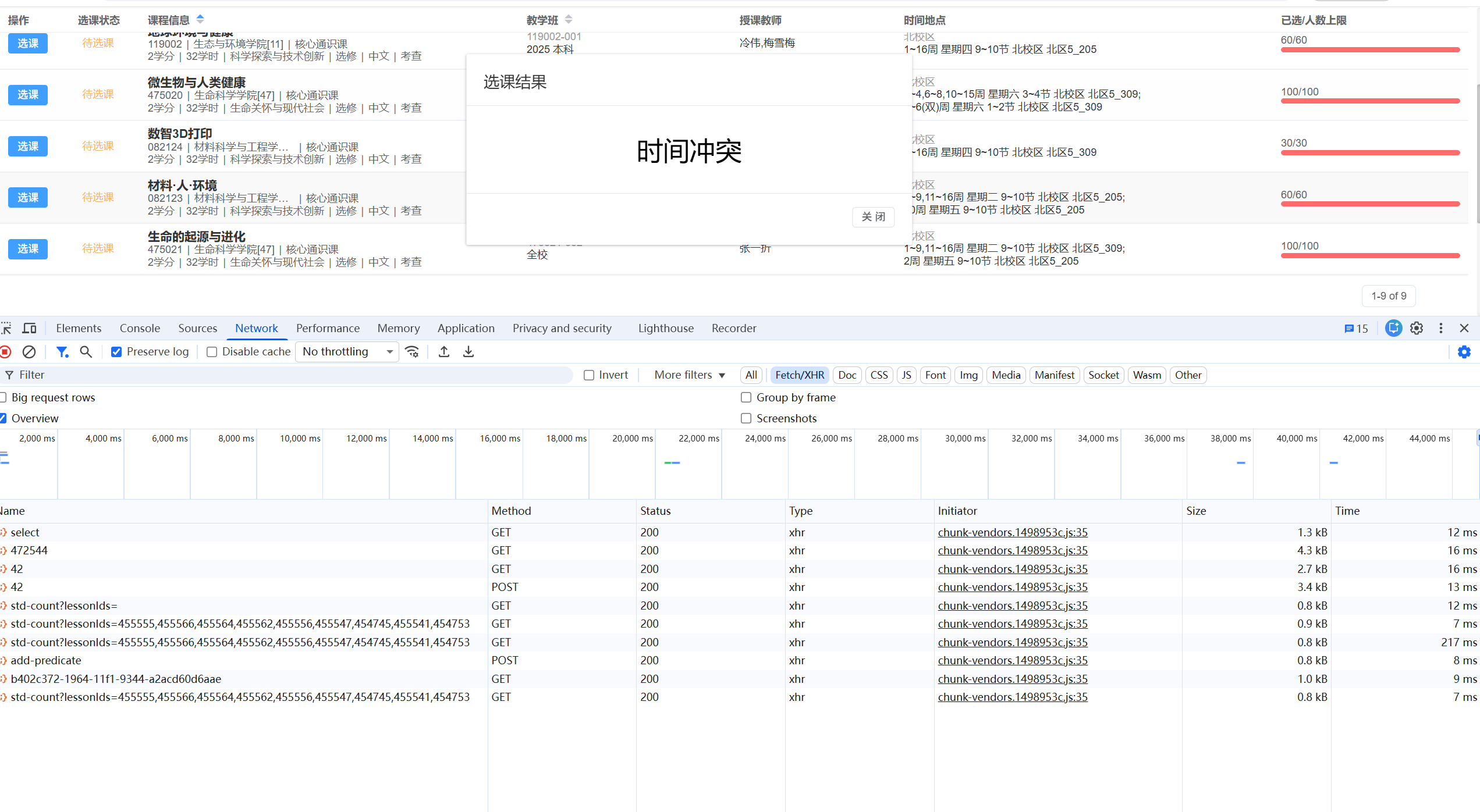
分析选课原理 首先当时的场景是“全红”,但不耽误我点按钮。只不过反馈变成了这样:
“时间冲突”代表这个课跟我们必修课的时间撞了,就算有名额也选不了。
“教学班人数已满”代表这个课能选,只是暂时没名额了,脚本应该专注于这一部分。
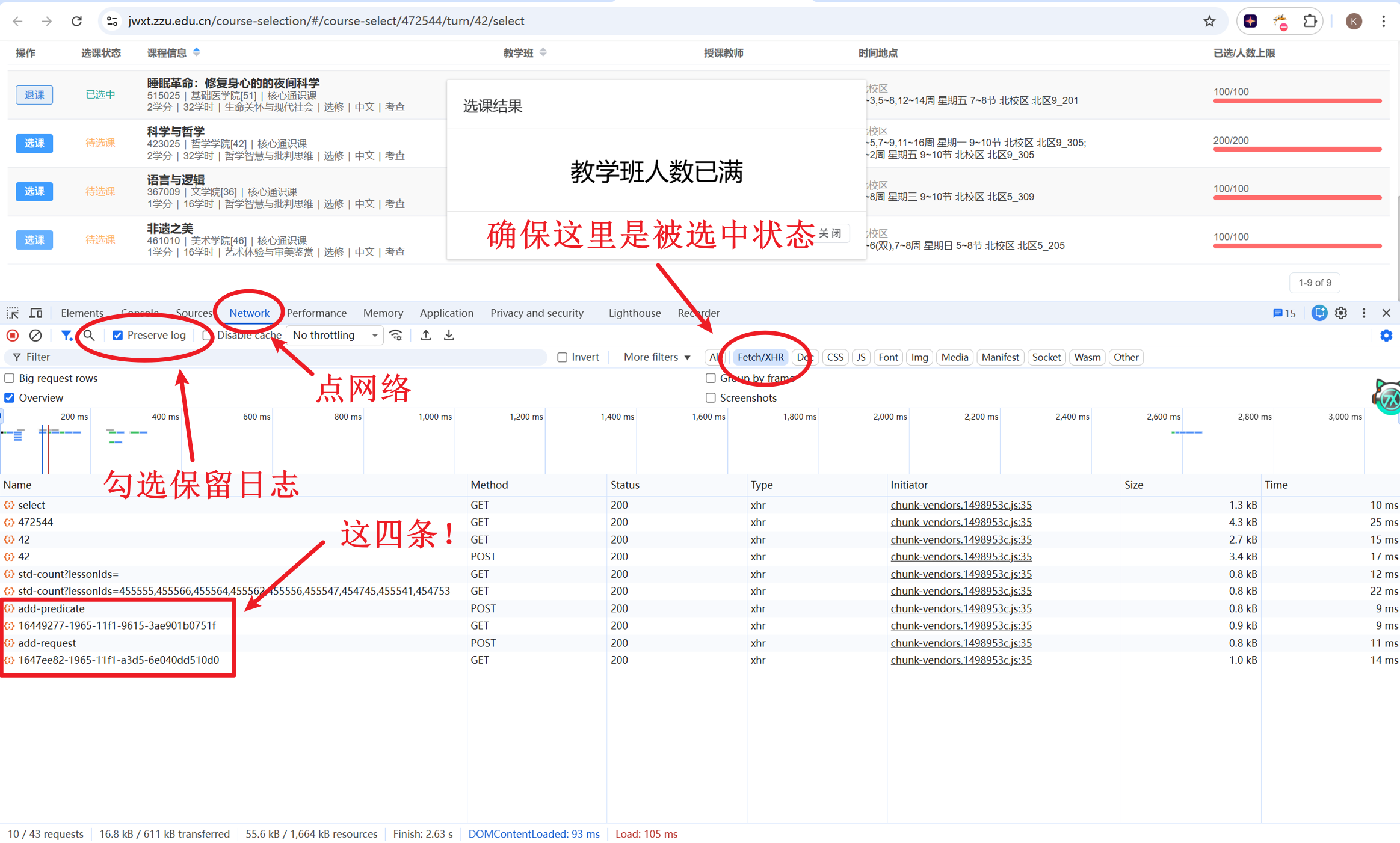
F12开控制台,勾选Preserve log(保留记录),确保选中Fetch/XHR(默认是选中的)。刷新一下页面,随便找个人数已满的课点一下选课,可以看到蹦出来四条请求。
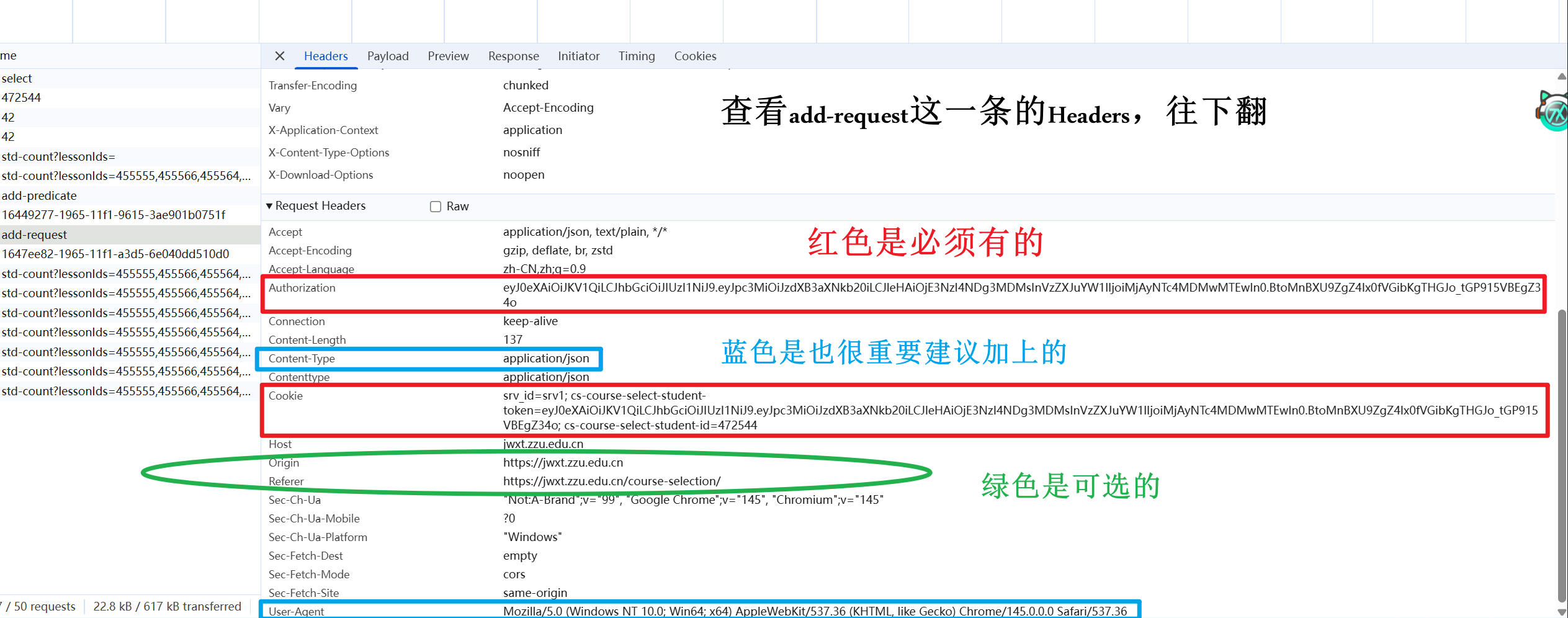
点一下请求就能看到它的具体信息。以add-request这条为例:
能看到这是一个POST请求,上方一栏可以查看它的Headers,Payload等属性。默认在Headers。
你可能要问:为什么先看add-request?
答:从名字推断的。”add-predicate”听起来更像预处理请求,只是做了一些准备工作,但并没有实际改变系统状态,可以跳过。
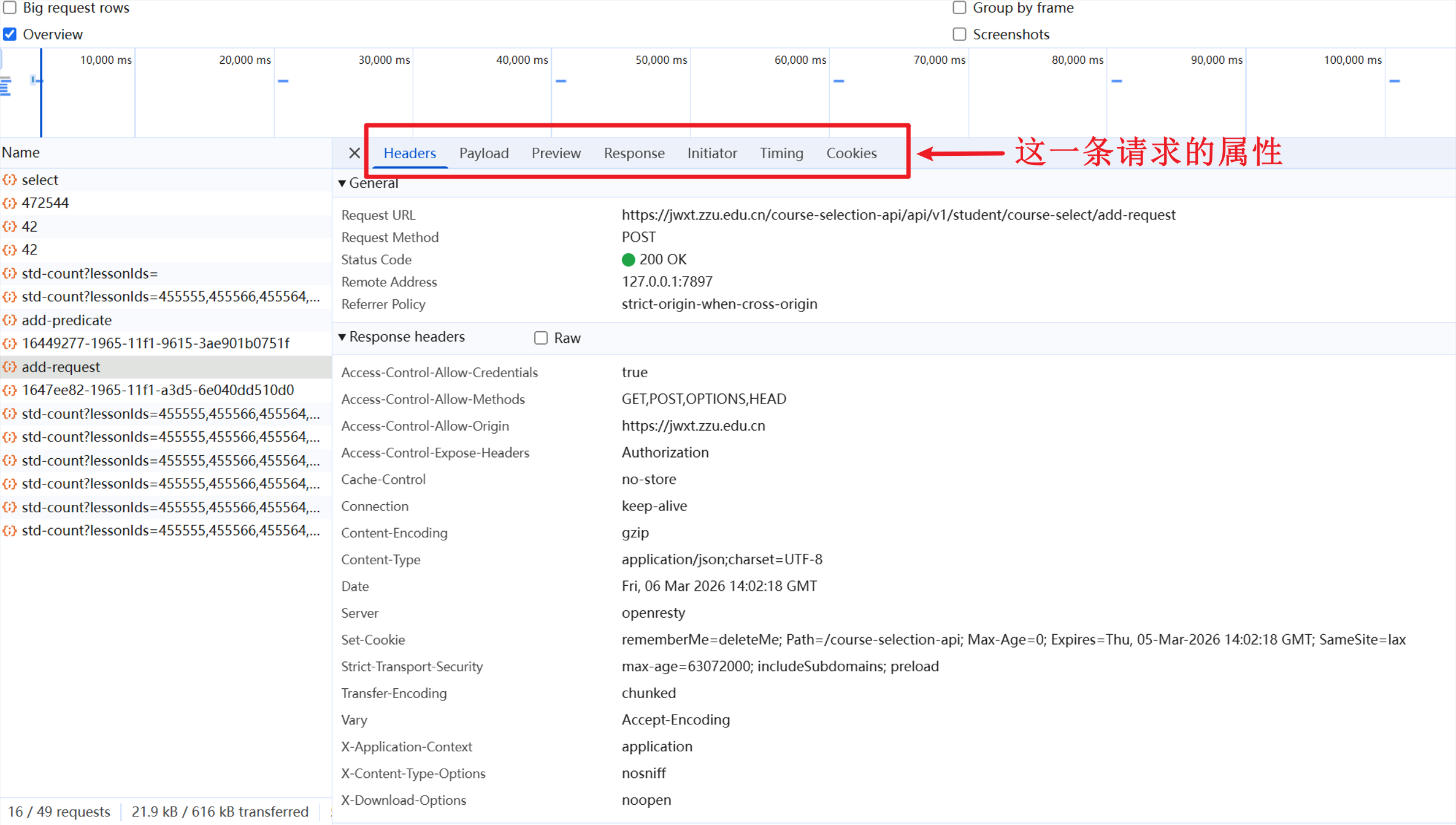
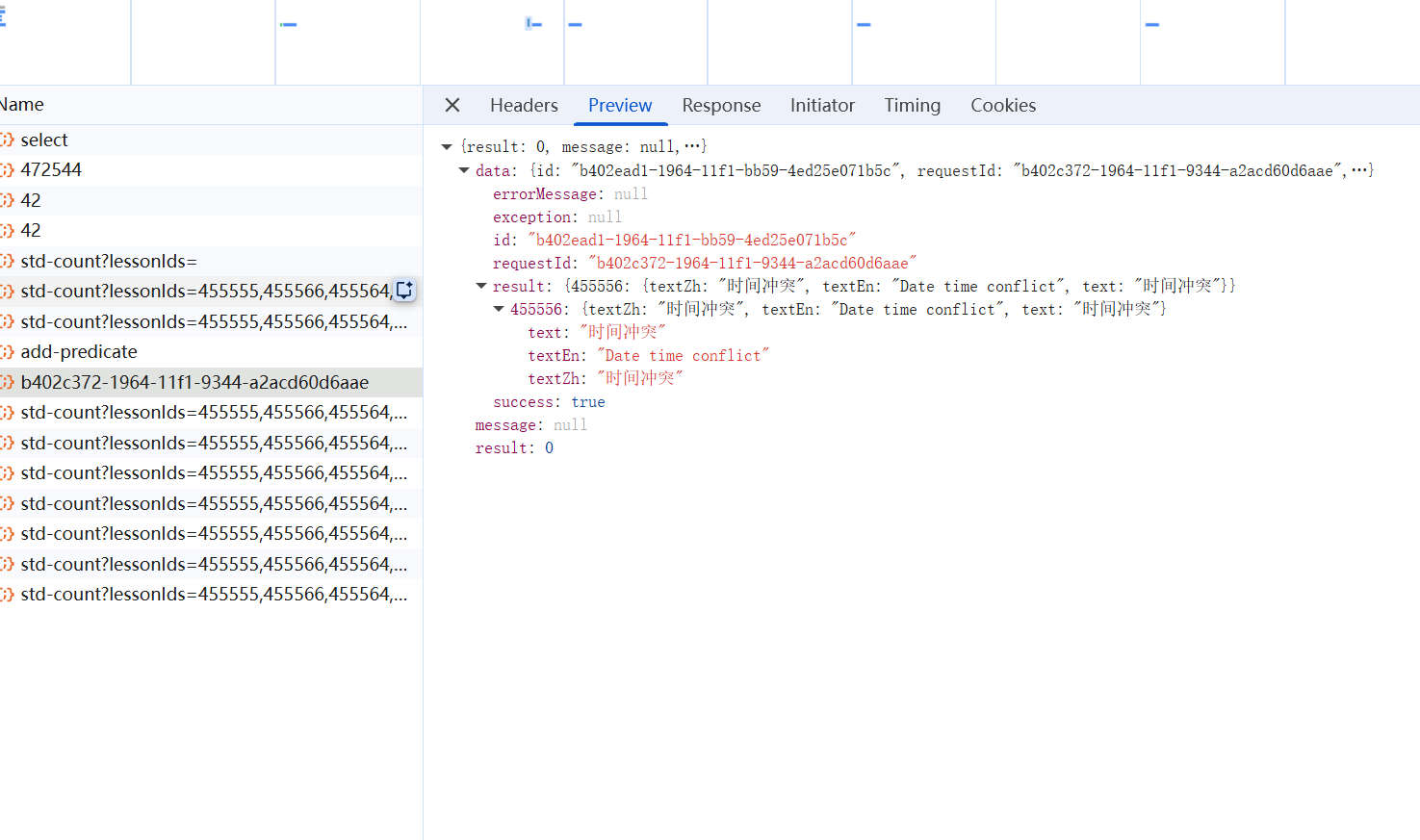
先点击Preview,这里是系统的返回结果,且是浏览器帮你解析好的 JSON。跟Response的原始信息相比,新手更容易看懂。
只有寥寥几行
1 2 3 4 { result: 0 , message: null , data: "1647ee82-1965-11f1-a3d5-6e040dd510d0" } : "1647ee82-1965-11f1-a3d5-6e040dd510d0" : null : 0
其中result:0是系统的标准响应,意味着请求已经成功到达并被系统接受。data返回了请求ID,但是没有告诉我们请求成功还是失败。
这时注意到add-request后下一条请求的名字,这不就是data的内容吗。于是查看它,这是个GET。点击Preview
看到这些信息
1 2 3 4 5 6 { "success" : false , "errorMessage" : { "text" : "教学班人数已满" } }
这里给出了本次选课的结果:false,此外发现1647ee82-1965-11f1-a3d5-6e040dd510d0作为requestId出现。如此大致看出模式:
先发送一条POST add-request拿到requestId,再用requestId发送GET获得返回结果。失败了的话,success这一条是false,那么不难推断成功了应该变成true。
所以对每一次选课操作,我们要做的就是:先构造并发送POST请求,再用GET查询结果。
又因为发送请求和返回结果是异步的,一条POST过去后可以进行多次GET查询,确保结果出现并接收。
了解了原理后,接下来的任务已经很明确了:构建HTTP请求。
根据web小知识,一条HTTP请求包括:请求行、请求头和请求体。
请求行一般包括请求方法和接口路径。请求方法就是POST、GET之类,接口路径的话,直接照抄原有的就行。
请求头包括一些身份、格式等附加信息。必不可少的有Authorization和Cookie,其他的也建议加上。
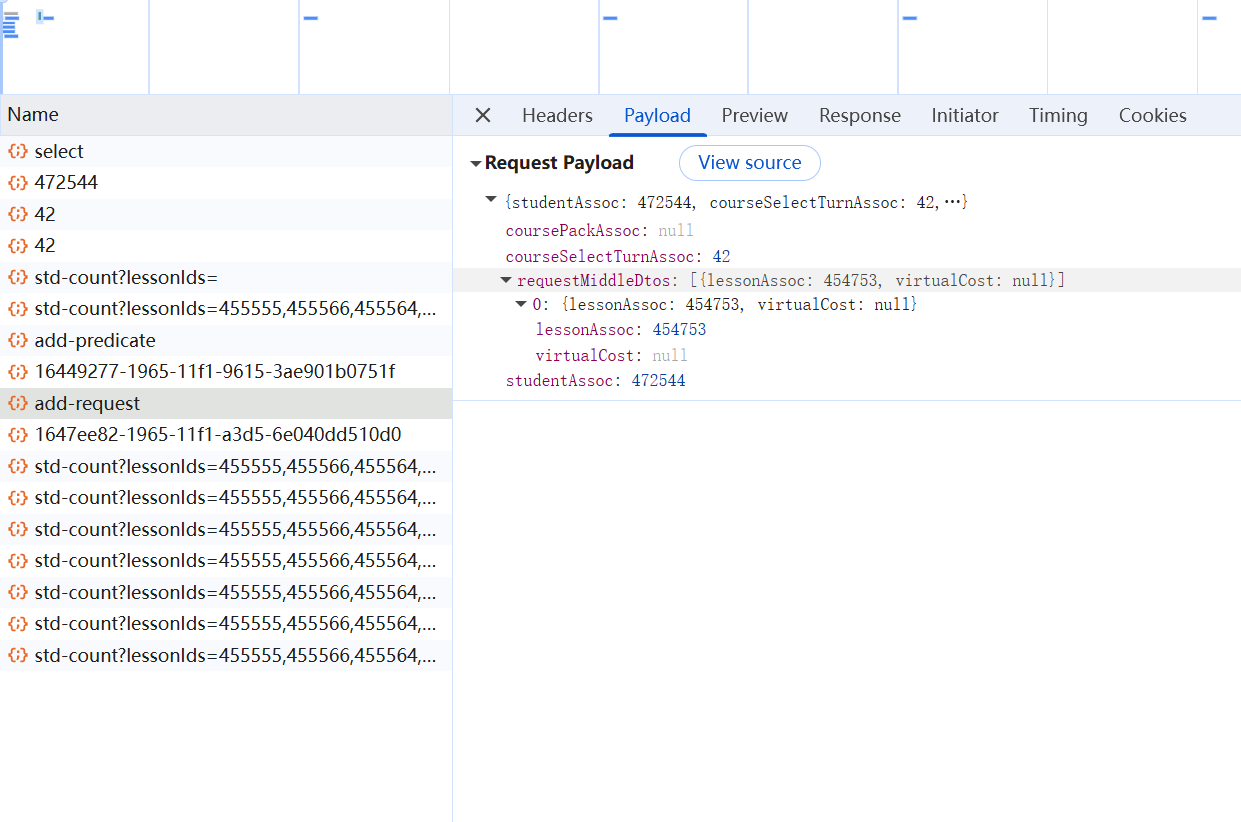
请求体就是携带的数据,也是直接复制浏览器返回的JSON,把关键字段一改就可以。
OK,开始构建!(最终包装为api_sniper_task(session, token, cookies, lesson_id))
请求的构建与发送 先进行一个库的引用环节。选课部分要使用的库,隆重介绍requests——Python 中最受欢迎的 HTTP 库,让网络请求变得像说话一样自然。跟HTTP请求挂钩的,用requests就对了。另外,还使用了time来进行时间层面的控制。
请求行的接口路径就是上上一张图中Request URL部分,复制下来。
1 https:// jwxt.zzu.edu.cn/course-selection-api/ api/v1/ student/course-select/ add-request
建议把/add-request前的部分单独保存为一个base参数,组装时再拼接,这样方便单独管理。
请求头headers如图所示
代码表述
1 2 3 4 5 6 7 8 headers = {"authorization" : token,"cookie" : cookies,"content-type" : "application/json" ,"user-agent" : "Mozilla/5.0" ,"referer" : "https://jwxt.zzu.edu.cn/course-selection/" ,"origin" : "https://jwxt.zzu.edu.cn"
其中Authorization和Cookie是动态的,会变化、会过期,必须实时获取。所以用参数替代,前面还得再加一个获取这两个值的函数。
对user-agent部分,加这个是要伪装成浏览器请求。大部分浏览器检验这一点只看”Mozilla/5.0”就会放行,所以我们也只采用这一部分。毕竟啊毕竟,你郑做的系统能指望有多严的防护()😂
请求体payload照搬add-request的payload
1 2 3 4 5 6 7 8 payload = {"studentAssoc" : STUDENT_ID,"courseSelectTurnAssoc" : TURN_ID,"coursePackAssoc" : None ,"requestMiddleDtos" : ["lessonAssoc" : lesson_id, "virtualCost" : None }
其中STUDENT_ID和TURN_ID替换成你实际的数据。
超级拼装为完整的请求并发送
1 2 3 4 5 6 post_resp = session.post(f"{api_base} /add-request" ,3
发送完首先确定发送成功了没有,用状态码来判断
1 2 if post_resp.status_code == 401 :return "RELOGIN" , "Token失效" , 0
如果你的登陆过期了状态码会变为401(未授权),这时候token失效,只能重新登录。
成功发送请求后获取requestId,失败就报错说明原因
1 2 3 req_id = post_resp.json().get("data" )if not req_id:return False , "无req_id" , 0
GET 查询阶段可以做一个循环
1 2 3 4 5 6 7 for _ in range (5 ): 0.06 ) f"{api_base} /add-drop-response/{STUDENT_ID} /{req_id} " , 3
下一步获取并返回该次请求的结果
1 2 3 4 5 6 7 8 9 10 res_data = get_resp.json().get("data" , {}) if res_data.get("success" ) is True :int ((time.time() - start_time) * 1000 ) return True , "成功" , latencyelif res_data.get("success" ) is False :"errorMessage" , {}).get("text" , "未知错误" ) int ((time.time() - start_time) * 1000 )return False , msg, latency
最后用try-excpet包装,选课请求函数大功告成。
鉴权资产的提取 下面处理Authorization和Cookie的获取问题。
观察发现Authorization的值就是Cookie中的token部分。我们只需要这样写
1 2 3 4 5 6 7 8 9 10 11 12 cookies = driver.get_cookies() "; " .join([f"{c['name' ]} ={c['value' ]} " for c in cookies]) None for c in cookies: if 'token' in c['name' ].lower():'value' ]break if not token:"return window.localStorage.getItem('token');" ) return token, cookie_str
然后依旧try-excpet包装。
刷新与保活机制 这一部分写在main函数中,先单独解释一下怎么实现。
库的使用方面,time于此大显身手,因为我们要计算时间来执行定期的刷新保活。
一开始我完全站在人类的角度思考,刷新页面的目的是“看课程有没有余量”,看到了就拼手速,脚本只是加速这个过程。
但了解了选课机制后我发现,这么做反而降低了效率。
仔细想想就能明白,我们设想的是选定一个特定科目后,持续不断的对其发送选课请求。期间cookie会过期,此时token也一并失效,请求会失败。所以只要让脚本在这种失败的条件下自动回到登录环节跑一遍流程,然后重新开始发送请求就行了,根本不用管有没有余量。咱们只看结果。
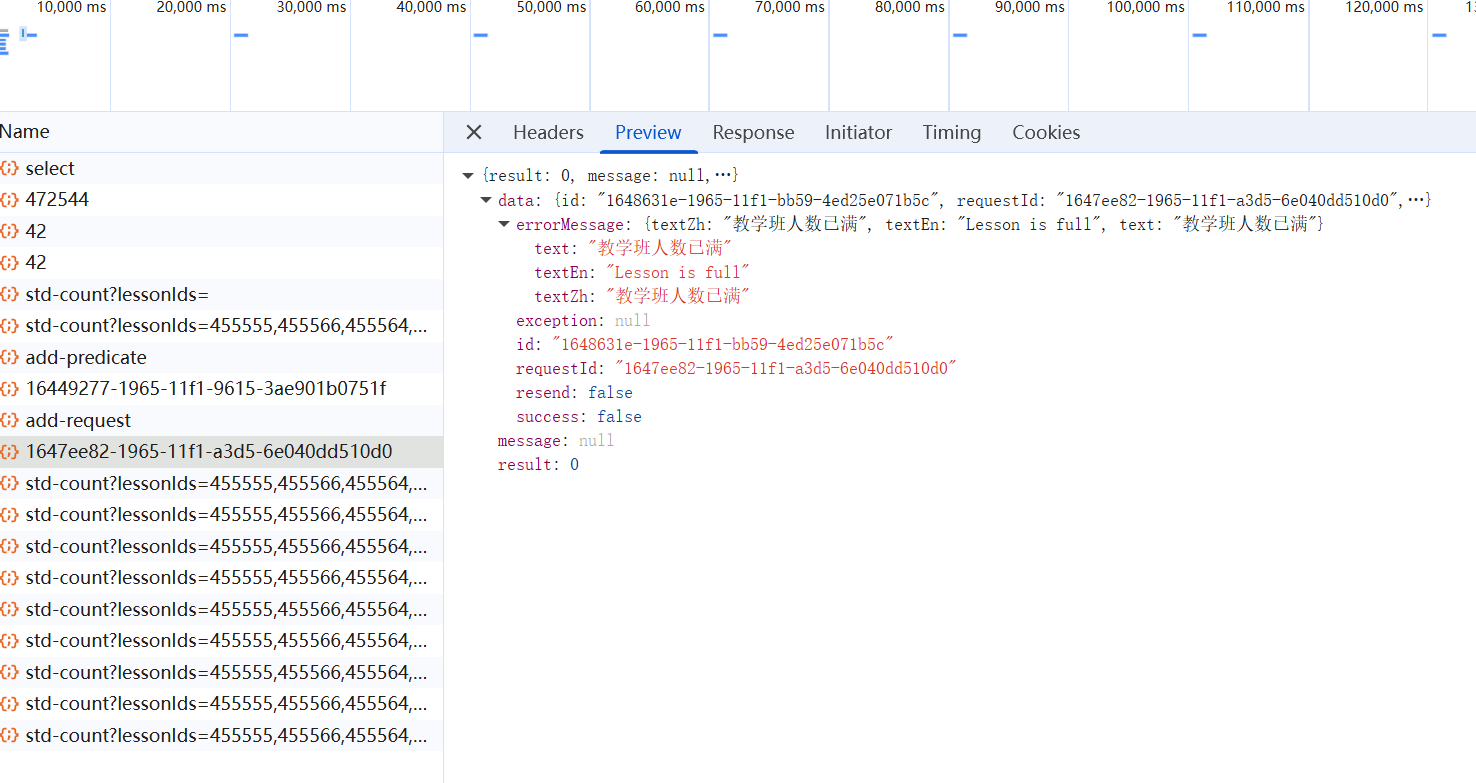
但在实测过程中,我发现网页每隔一段时间就会出现一条新的请求(也就是心跳请求):
那一堆std-count?开头的就是。虽然当时没有截里面的内容(后来在朋友的聊天记录中找到了有点糊的截图),但是能记得这个请求是个GET,作用是检测课程状态。在它的Response中可以看到这样的data(仅举三例):
1 2 3 "455556" : "100-0-0" ; "455541" : "100-0-0" ; "455555" : "100-0-0" ;
不难猜到前面的数字代表课程编号,后面代表“人数总量-当前余量”。
而且一旦登录过期,这个GET的状态码就会变成401。好家伙,直接帮我们解决了两个问题:检测课程余量和检测登录状态。现成的机制不用白不用,我们直接利用它来实现保活。
根据我前面的描述,你大概能想到main中的完整机制应该是一个循环。我们直接while True起手:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 while True : for l_id in TARGET_LESSONS:if not token: if not token:print (f"{Fore.RED} 无法提取 Token" )2 )continue 1 '%H:%M:%S' ) if success else (Fore.YELLOW if "满" in msg else Fore.RED) print (f"\r{Fore.WHITE} [{ts} ] {Fore.BLUE} 目标:{l_id} " f"{Fore.CYAN} 第{attempts} 次 {color} 状态:{msg} " f"{Fore.GREEN} 延迟:{lat} ms" ,"" if success:print (f"\n\n{Fore.GREEN} 选课成功,课程 {l_id} 已抢到" )if os.name == 'nt' : import winsoundfor _ in range (5 ):1000 , 300 )return
以上是正常选课流程,接下来做登录失效的检测和处理。这里保留了POST接口检测token失效的方法作为双保险,注意我写的判断条件只是假设,因为博主这一块的截图找不到了(悲)
1 2 3 4 5 6 7 8 9 10 11 12 13 if success == "RELOGIN" :print (f"\n{Fore.MAGENTA} POST检测到失效,重新登录中..." )if not run_login_flow(driver):print (f"{Fore.RED} 重新登录失败" )continue print (f"{Fore.GREEN} 登录恢复成功" )break
然后是心跳检测的实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 if time.time() - last_check > 5 : if not check_alive():print (f"\n{Fore.MAGENTA} 心跳检测:登录已失效,重新登录中..." )if not run_login_flow(driver):print (f"{Fore.RED} 重新登录失败" )continue if not token:print (f"{Fore.RED} Token 获取失败" )continue print (f"{Fore.GREEN} 登录恢复成功" )
其中心跳检测函数check_alive用于模拟系统的心跳请求,内容为
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 def check_alive ():try :"https://jwxt.zzu.edu.cn/course-selection-api/api/v1/student/course-select/std-count" "lessonIds" : "," .join(map (str , TARGET_LESSONS))"authorization" : token,"cookie" : cookies,"user-agent" : "Mozilla/5.0" ,"referer" : "https://jwxt.zzu.edu.cn/course-selection/" 3 )if resp.status_code == 401 :return False return True except :return True
最后,经过测试,token失效的时间差不多是13分钟。所以在循环中加一个每13分钟执行一次的强制刷新
1 2 3 4 5 6 7 8 9 10 11 12 13 14 if time.time() - last_refresh > 780 :print (f"\n{Fore.MAGENTA} [{time.strftime('%H:%M:%S' )} ] 兜底刷新 Token..." )5 )if not token:print (f"{Fore.RED} 刷新后 Token 获取失败" )continue print (f"{Fore.GREEN} Token 已更新" )
整个原理就是由脚本伪造并主动发送那个心跳GET,从状态码中判断登录是否失效。同时脚本也会从选课请求的返回内容进行验证,还有强制刷新机制兜底。无论哪一关发现问题,脚本都会触发重新获取凭证的机制确保选课请求不受影响。
主播主播,你说的这个心跳机制不是系统自带的吗,那直接获取每条GET的状态码不就行了,何必大费周章自己构建呢?
好问题。首先浏览器自带的心跳检测机制是人家设计好的,频率都是固定的,一般情况下慢于我们的请求频率,导致我们没法及时地检验登录状态。这点其实还好,我们设置了双保险。
但更重要的是,这个请求只存在于浏览器内部的网络层 ,是浏览器里的前端 JS 在发。而我们的request库拿不到浏览器的网络数据,所以只能仿照结构自己构建发送可控的请求,这比偷看浏览器请求容易多了。
如此,这部分也圆满完成了。
最后的整合 终于走到这一步了。话不多说,直接放出完整脚本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 import timeimport requestsimport osfrom selenium import webdriverfrom selenium.webdriver.common.by import Byfrom selenium.webdriver.support.ui import WebDriverWaitfrom selenium.webdriver.support import expected_conditions as ECfrom selenium.webdriver.common.keys import Keysfrom selenium.webdriver.common.action_chains import ActionChainsfrom colorama import Fore, Style, initTrue )"学号" "密码" "你的STUDENT_ID" "选课轮次ID" 123456 ] "https://cas.s.zzu.edu.cn/cas/s/login?service=https%3A%2F%2Fjwxt.zzu.edu.cn%2Fstudent%2Fsso%2Flogin" def run_login_flow (driver ):"""登录及穿透遮罩逻辑""" try :20 )print (Fore.CYAN + "登录中..." )"input[placeholder='请输入学号/工号']" ))).send_keys(USERNAME)"input[placeholder='请输入统一身份认证密码']" ).send_keys(PASSWORD)"login-btn" ).click()print (Fore.CYAN + "进入选课入口..." )"//div[contains(@class,'shortcut-item') and .//div[contains(text(),'选课')]]" )))"arguments[0].click();" , course_icon)2 )print (Fore.CYAN + "穿透系统遮罩..." )"//span[contains(text(),'上次登录时间')]" )))0.5 )print (Fore.CYAN + "发送键盘指令..." )for _ in range (3 ):0.3 )print (Fore.CYAN + "等待选课系统加载..." )for _ in range (15 ):1 )for handle in driver.window_handles:if "course-selection" in driver.current_url:print (Fore.GREEN + "成功进入选课系统" )return True return False except Exception as e:print (f"{Fore.RED} ❌ 登录异常: {e} " )return False def get_auth_assets (driver ):"""提取鉴权资产""" try :"; " .join([f"{c['name' ]} ={c['value' ]} " for c in cookies])"return window.localStorage.getItem('token');" )if not token:for c in cookies:if 'token' in c['name' ].lower():'value' ]return token, cookie_strexcept :return None , None def api_sniper_task (session, token, cookies, lesson_id ):"""API 抢课任务""" "https://jwxt.zzu.edu.cn/course-selection-api/api/v1/student/course-select" "authorization" : token,"cookie" : cookies,"content-type" : "application/json" ,"user-agent" : "Mozilla/5.0" ,"referer" : "https://jwxt.zzu.edu.cn/course-selection/" ,"origin" : "https://jwxt.zzu.edu.cn" "studentAssoc" : STUDENT_ID,"courseSelectTurnAssoc" : TURN_ID,"coursePackAssoc" : None ,"requestMiddleDtos" : [{"lessonAssoc" : lesson_id, "virtualCost" : None }]try :f"{api_base} /add-request" , json=payload, headers=headers, timeout=3 )if post_resp.status_code == 401 :return "RELOGIN" , "Token失效" , 0 "data" )if not req_id: return False , "无req_id" , 0 for _ in range (5 ):0.06 )f"{api_base} /add-drop-response/{STUDENT_ID} /{req_id} " , headers=headers, timeout=3 )"data" , {})if res_data.get("success" ) is True :return True , "成功" , int ((time.time() - start_time) * 1000 )if res_data.get("errorMessage" ):return False , res_data["errorMessage" ]["text" ], int ((time.time() - start_time) * 1000 )return False , "排队中" , 0 except :return False , "网络异常" , 0 def main ():"detach" , True )print ("启动 ChromeDriver..." )print ("ChromeDriver 启动成功" )if not run_login_flow(driver):print (f"{Fore.RED} ❌ 登录流程失败,请手动检查浏览器。" )return if not token:print (f"{Fore.RED} ❌ 初始 Token 获取失败" )return 0 0 print (f"\n{Fore.CYAN} 🚀 API 引擎启动 | 目标: {TARGET_LESSONS} " )def check_alive ():try :"https://jwxt.zzu.edu.cn/course-selection-api/api/v1/student/course-select/std-count" "lessonIds" : "," .join(map (str , TARGET_LESSONS))"authorization" : token,"cookie" : cookies,"user-agent" : "Mozilla/5.0" ,"referer" : "https://jwxt.zzu.edu.cn/course-selection/" 3 )if resp.status_code == 401 :return False return True except :return True try :while True :if time.time() - last_check > 5 :if not check_alive():print (f"\n{Fore.MAGENTA} ⚠️ 心跳检测:登录已失效,重新登录中..." )if not run_login_flow(driver):print (f"{Fore.RED} ❌ 重新登录失败" )continue nonlocal token, cookies if not token:print (f"{Fore.RED} ❌ Token 获取失败" )continue print (f"{Fore.GREEN} ✅ 登录恢复成功" )if time.time() - last_refresh > 780 :print (f"\n{Fore.MAGENTA} [{time.strftime('%H:%M:%S' )} ] 🔄 兜底刷新 Token..." )5 )if not token:print (f"{Fore.RED} ⚠️ 刷新后 Token 获取失败" )continue print (f"{Fore.GREEN} ✅ Token 已更新" )for l_id in TARGET_LESSONS:1 '%H:%M:%S' )if success else (Fore.YELLOW if "满" in msg else Fore.RED)print (f"\r{Fore.WHITE} [{ts} ] {Fore.BLUE} 目标:{l_id} " f"{Fore.CYAN} 第{attempts} 次 {color} 状态:{msg} " f"{Fore.GREEN} 延迟:{lat} ms" ,"" if success is True :print (f"\n\n{Fore.GREEN} 🎊 ★★★ 选课成功!课程 {l_id} 已抢到 ★★★" )if os.name == 'nt' :import winsoundfor _ in range (5 ):1000 , 500 )return if success == "RELOGIN" :print (f"\n{Fore.MAGENTA} ⚠️ POST检测到失效,重新登录中..." )if not run_login_flow(driver):print (f"{Fore.RED} ❌ 重新登录失败" )continue print (f"{Fore.GREEN} ✅ 登录恢复成功" )break 0.3 )except KeyboardInterrupt:print (f"\n{Fore.RED} 🛑 手动终止。" )finally :print ("脚本运行结束。" )if __name__ == "__main__" :
完整脚本除了拼装登录和选课部分的所有函数和代码块外,还进行了一些结构上的优化。比如单独设置了一个“个人配置中心”,可以自定义一些因人而异的数据;引入colorama来优化信息显示等等。
主函数部分利用ChromeDriver启动了一个独立的窗口,充当登录载体和 Token 提取池,能够处理复杂的身份验证。优点是降低了脚本编写难度,增强系统容错,并利用真实浏览器环境有效规避了简单的行为风控。
但我们这种速成的半吊子选手写的脚本还是免不了有些问题,比如变量作用域冲突、死循环中的异常崩溃、以及高频请求下的同步阻塞之类的。
写到这里孩子已经燃尽了,那就扔给ai大人优化一下吧。以下是ai给出的优化方案,博主打算等系统再次开放去跑一下试试:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 def main ():"token" : None ,"cookies" : None ,"last_refresh" : time.time(),"last_check" : 0 ,"attempts" : 0 if not run_login_flow(driver):return for _ in range (5 ):"token" ], ctx["cookies" ] = get_auth_assets(driver)if ctx["token" ]: break 1 )print (f"\n{Fore.CYAN} 🚀 结构优化版引擎启动" )def check_alive_internal ():"""心跳探测逻辑""" try :"https://jwxt.zzu.edu.cn/course-selection-api/api/v1/student/course-select/std-count" "lessonIds" : "," .join(map (str , TARGET_LESSONS))}"authorization" : ctx["token" ],"cookie" : ctx["cookies" ],"user-agent" : "Mozilla/5.0" 3 )return resp.status_code != 401 except :return True try :while True :try : if time.time() - ctx["last_check" ] > 5 :if not check_alive_internal():print (f"\n{Fore.MAGENTA} ⚠️ 掉线预警:正在自动执行重登恢复..." )if run_login_flow(driver):"token" ], ctx["cookies" ] = get_auth_assets(driver)"last_refresh" ] = time.time()print (f"{Fore.GREEN} ✅ 资产已重新同步" )else :print (f"{Fore.RED} ❌ 重登尝试失败,等待下一轮" )"last_check" ] = time.time()if time.time() - ctx["last_refresh" ] > 780 :3 )"token" ], ctx["cookies" ] = get_auth_assets(driver)"last_refresh" ] = time.time()print (f"\n{Fore.BLUE} 🔄 定期维护:已刷新浏览器环境" )for l_id in TARGET_LESSONS:"attempts" ] += 1 "token" ], ctx["cookies" ], l_id)if success == "RELOGIN" :"last_check" ] = 0 break print (f"\r[{time.strftime('%H:%M:%S' )} ] 目标:{l_id} 次数:{ctx['attempts' ]} 状态:{msg} " , end="" )if success is True :print (f"\n{Fore.GREEN} 🎊 任务圆满完成!" )return 0.3 )except requests.exceptions.RequestException as e:print (f"\n{Fore.YELLOW} 📡 网络异常(已拦截): {e} ,正在重试..." )1 ) except KeyboardInterrupt:print ("\n🛑 用户手动终止" )
呼,到这里,虽然细节方面仍不完美,但至少已经满足了我们一开始的选课需求。妈妈再也不用担心孩子选不到课了…吗?
别忘了我们这个脚本的预期使用情景:是课被抢完了之后等着有人退课去捡漏用的,那要是没人退课,也就只能认命了。
好像强制把已经选上课的人挤掉也不是不行……那种事情做不得啊喂!
所以还是有必要开发一个“火力全开”模式的。这个等未来有需求再说吧。
大学生与选课系统的斗争仍在继续。或许终有一天我能写出完美的选课脚本,但那时可能早就没有选课需求了。不过视野放宽点,无论过年回家抢车票,还是购物平台抢国补资格,似乎都有共通之处。这样想想,也算是没有完全在这次选课中败下阵来。
总之,希望这篇文章能帮到你,有什么更好的思路的话,欢迎分享哦。